I got access to our 12-core Intel server, so I was able to do some better benchmarks to test the different group commit thread scheduling methods:
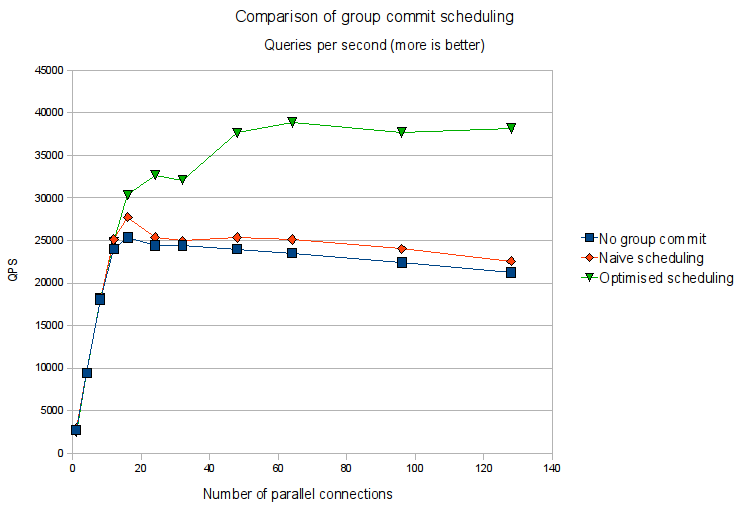
This graph shows queries-per-second as a function of number of parallel connections, for three test runs:
- Baseline MariaDB, without group commit.
- MariaDB with group commit, using the simple thread scheduling, where the serial part of the group commit algorithm is done by each thread signalling the next one.
- MariaDB with group commit and optimised thread scheduling, where the first thread does the serial group commit processing for all transactions at once, in a single thread.
(see the previous post linked above for a more detailed explanation of the two thread scheduling algorithms.)
This test was run on a 12-core server with hyper-threading, memory is 24 GByte. MariaDB was running with datadir in /dev/shm (Linux ram disk), to simulate a really fast disk system and maximise the stress on the CPUs. Binlog is enabled with sync_binlog=1 and innodb_flush_log_at_trx_commit=1. Table type is InnoDB.
I use Gypsy to generate the client load, which is simple auto-commit primary key updates:
REPLACE INTO t (a,b) VALUES (?, ?)
The graph clearly shows the optimised thread scheduling algorithm to improve scalability. As expected, the effect is more pronounced on the twelve-core server than on the 4-core machine I tested on previously. The optimised thread scheduling has around 50% higher throughput at higher concurrencies. While the naive thread scheduling algorithm suffers from scalability problems to the degree that it is only slightly better than no group commit at all (but remember that this is on ram disk, where group commit is hardly needed in the first place).
There is no doubt that this kind of optimised thread scheduling involves some complications and trickery. Running one part of a transaction in a different thread context from the rest does have the potential to cause subtle bugs.
On the other hand, we are moving fast towards more and more CPU cores and more and more I/O resources, and scalability just keeps getting more and more important. If we can scale MariaDB/MySQL with the hardware improvements, more and more applications can make do with scale-up rather than scale-out, which significantly simplifies the system architecture.
So I am just not comfortable introducing more serialisation (e.g. more global mutex contention) in the server than absolutely necessary. That is why I did the optimisation in the first place even without testing. Still, the question is if an optimisation that only has any effect above 20,000 commits per second is worth the extra complexity? I think I still need to think this over to finally make up my mind, and discuss with other MariaDB developers, but at least now we have a good basis for such discussion (and fortunately, the code is easy to change one way or the other).
Are your “No group commit” results obtained with binlog enabled or disabled?
If they are obtained with binlog enabled, the numbers seem extremely high. In your benchmark from last year (http://kristiannielsen.livejournal.com/12254.html) the performance with binlog enabled was extremely low, around 100 qps. But now even your baseline, no group commit performance is up at 25K qps. Why such a huge difference?
Andy
It is because of ram disk
Yes, the “no group commit” results are with binlog enabled.
The reason for the high throughput without group commit is that the data is in ramdisk, /dev/shm. That makes fsync() a no-operation. Since the main purpose of group commit is to reduce the number of fsync() calls, it does not make much difference here. In the other benchmark, data was on a real disk without a battery-backed-up raid controller cache, making fsync() very expensive.
In this benchmark I wanted to stress the algorithm with respect to CPU scalability (as opposed to I/O). The reason that we nevertheless see a good speedup from group commit on ram disk is reduced mutex contention in the new code.
Existing MySQL/MariaDB has a really expensive mutex inside InnoDB/XtraDB called prepare_commit_mutex; this serialises a much bigger part of the commit process.
Re: It is because of ram disk
I see. I missed the ramdisk part in your post.
Do you have benchmark data of your group commit code using disk or SSD? Currently with MySQL if I turned on binlog I’d get maybe a 90% drop in performance. What kind of performance drop would you expect with your group commit code?
Andy
Re: It is because of ram disk
Yes, here is a benchmark for both HDD and SSD:
https://knielsen-hq.org/w/fixing-mysql-group-commit-part-4-of-3/
The performance impact with group commit very much depends on the workload, it’s impossible to say something in general.
If there is high parallelism (many transactions commiting in parallel), group commit can help a lot (an order of magnitude in extreme cases). If there is no parallelism, group commit is unlikely to make much difference at all.
If you want, you can try it out yourself, there are both source and binaries available of MariaDB with group commit here:
http://kb.askmonty.org/v/mariadb-52-replication-feature-preview
(The above benchmark with HDD/SSD is on consumer-grade disks only, unfortunately. I am working on re-running it on better hardware, and then will also try to add the numbers for when binlog is disabled).
Re: It is because of ram disk
Thanks. Would love to see any comparison of the group commit solution to when the binlog is disabled. Do you expect a substantial performance drop when the binlog is enabled using your group commit fix?
My workload is highly parallel, with lots of autocommit inserts and updates concurrently. I can’t use replication because enabling binlog killed the performance. I’ve seen several solutions:
1) PBXT replication. No binlog needed.
2) HandlerSocket. It groups multiple writes and execute them inside a single transaction. They reported 30,000 write requests per sec on HDD even with sync_binlog = 1, innodb_support_xa = 1
3) Your group commit fix
How do you see them compared to each others? Pros and cons?
Andy
“the question is if an optimisation that only has any effect above 20,000 commits per second is worth the extra complexity?”
Obviously this depends on how much extra complexity vs. how much extra performance. But I think 20,000 commits per second is not that much. Right now you can spend $200 on an SSD that gives you 50,000 write IOPS without RAID. FusionIO can give you 200,000 IOPS. And these numbers will only go up with each generation of SSD.
Good
great post as usual!
It is worth it
Yes, it’s worth it for an optimization that only kicks in for 20k commits per second and over. I’d like to see how this affects a more realistic workload on an even larger server. I believe that the value would be clear. I’ve asked Vadim whether we could get you access to such a server.