I found time to continue my previous work on group commit for the binary log in MariaDB.
In current code, a (group) commit to InnoDB does not less than three fsync() calls:
- Once during InnoDB prepare, to make sure we can recover the transaction in InnoDB if we crash after writing it to the binlog.
- Once after binlog write, to make sure we have the transaction in the binlog before we irrevocably commit it in InnoDB.
- Once during InnoDB commit, to make sure we no longer need to scan the binlog after a crash to recover the transaction.
Of course, in point 3, it really is not necessary to do an fsync() after every (group) commit. In fact, it seems hardly necessary to do such fsync() at all! If we should crash before the commit record hits the disk, we can always recover the transaction by scanning the binlogs and checking which of the transactions in InnoDB prepared state should be committed. Of course, we do not want to keep and scan years worth of binlogs, but we need only fsync() every so often, not after every commit.
So I implemented MDEV-232. This removes the fsync() call in the commit step in InnoDB. Instead, the binlog code requests from InnoDB (and any other transactional storage engines) to flush all pending commits to disk when the binlog is rotated. When InnoDB is done with the flush, it reports back to the binlog code. We keep track of how far InnoDB has flushed by writing so-called checkpoint events into the current binlog. After a crash, we first scan the latest binlog. The last checkpoint event found will tell us if we need to scan any older binlogs to be sure to find all commits that were not durably committed inside InnoDB prior to the crash.
The result is that we only need to do two fsync() calls per (group) commit instead of three.
I benchmarked the code on a server with a good disk system – HP RAID controller with a battery-backed up disk cache. When the cache is enabled, fsync() is fast, around 400 microseconds. When the cache is disabled, it is slow, several microseconds. The setup should be mostly comparable to Mark Callaghan’s benchmarks here and here.
I used sysbench update_non_index.lua to make it easier for others to understand/reproduce the test. This does a single update of one row in a table in each transaction. I used 100,000 rows in the table. Group commit is now so fast that at higher concurrencies, it is no longer the bottleneck. It will be interesting to test again with the new InnoDB code from MySQL 5.6 and any other scalability improvements that have been made there.
Slow fsync()
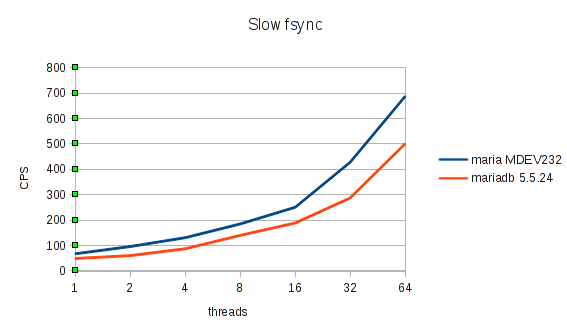
As can be seen, we have a very substantial improvement, around 30-60% more commits per second depending on concurrency. Not only are we saving one out of three expensive fsync() calls, improvements to the locking done during commit also allow more commits to share the same fsync().
Fast fsync()
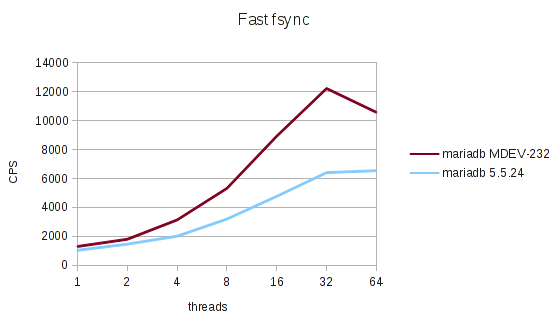
Even with fast fsync(), the improvements are substantial.
I am fairly pleased with these results. There is still substantial overhead from enabling the binlog (like several times slowdown if fsync() time is the bottleneck), and I have a design for mostly solving this in MWL#164. But I think perhaps it is now time to turn towards other more important areas. In particular I would like to turn to MWL#184 – another method for parallel apply of events on slaves that can help in cases where the per-database split of workload that exists in Tungsten and MySQL 5.6 can not be used, like many updates to a single table. Improving throughput even further on the master may not be the most important if slaves are already struggling to keep up with current throughput, and this is another relatively simple spin-off from group commit that could greatly help.
For anyone interested, the current code is pushed to lp:~maria-captains/maria/5.5-mdev232
MySQL group commit
It was an interesting coincidence that the new MySQL group commit preview was
published just as I was finishing this work. So I had the
chance to take a quick look and include it in the benchmarks (with slowfsync()):
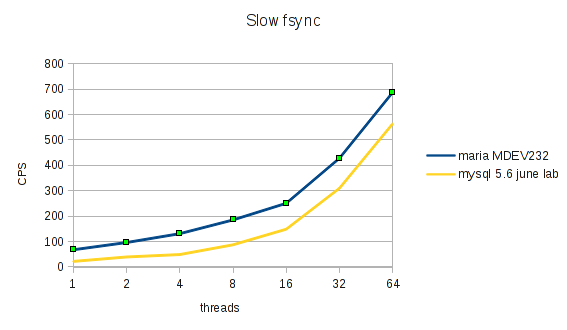
While the implementation in MySQL 5.6 preview is completely different from MariaDB (talk about “not invented here …”), the basic design is now quite similar, as far as I could gather from the code. A single thread writes all transactions in the group into the binlog, in order; likewise a single thread does the commits (to memory) inside InnoDB, in order. The storage engine interface is extended with a thd_get_durability_property() callback for the engines – when the server returns HA_IGNORE_DURABILITY from this, InnoDB commit() method is changed to work exactly like MariaDB commit_ordered(): commit to memory but do not sync to disk.
(It remains to see what storage engine developers will think of MySQL implementing a different API for the same functionality …)
The new MySQL group commit also removes the third fsync() in the InnoDB commit, same as the new MariaDB code. To ensure they can still recover after a crash, they just call into the storage engines to sync all commits to disk during binlog rotate. I actually like that from the point of simplicity – even if it does stall commits for longer, it is unlikely to matter in practice. What actually happens inside InnoDB in the two implementations is identical.
The new MySQL group commit is substantially slower than the new MariaDB group commit in this benchmark. My guess is that this is in part due to suboptimal inter-thread communication. As I wrote about earlier, this is crucial to get best performance at high commit rates, and the MySQL code seems to do additional synchronisation between what they call stages – binlog write, binlog fsync(), and storage engine commit. Since the designs are now basically identical, it should not be hard to get this fixed to perform the same as MariaDB. (Of course, if they had started from my work, they could have spent the effort improving that even more, rather than wasting it on catch-up).
Note that the speedup from group commit (any version of it) is highly dependent on the workload and the speed of the disk system. With fast transactions, slow fsync(), and high concurrency, the speedup will be huge. With long transactions, fast fsync(), and low concurrency, the speedups will be modest, if any.
Incidentally, the new MySQL group commit is a change from the designs described earlier, where individual commit threads would use pwrite() in parallel into the binary log. I am convinced this is a good change. The writing to binlog is just memcpy() between buffers, a single thread can do gigabytes worth of that, it is not where the bottleneck is. While it is crucial to optimise the inter-thread communication, as I found out here – and lots of small parallel pwrite() calls into the same few data blocks at the end of a file delivered to the file system is not likely to be a success. If binlog write bandwidth would really turn out to be a problem the solution is to have multiple logs in parallel – but I think we are quite far from being there yet.
It is a pity that we cannot work together in the MySQL world. I approached the MySQL developers several times over the past few years suggesting we work together, with no success. There are trivial bugs in the MySQL group commit preview whose fix yield great speedup. I could certainly have used more input while doing my implementation. The MySQL user community could have much better quality if we would only work together.
Instead, Oracle engineers use their own bugtracker which is not accessible to others, push to their own development trees which are not accessible to others, communicate on their own mailing lists which are not accessible to others, hold their own developer meetings which are not accessible to others … the list is endless.
The most important task when MySQL was aquired was to collect the different development groups working on the code base and create a real, great, collaborative Open Source project. Oracle has totally botched this task up. Instead, what we have is lots of groups each working on their own tree, with no real interesting in collaborating. I am amazed every time I read some prominent MySQL community member praise the Oracle stewardship of MySQL. If these people are not interested in creating a healthy Open Source project and just want to not pay for their database software, why do they not go use the express/cost-free editions of SQL server or Oracle or whatever?
It is kind of sad, really.
It is not just inter-thread communication. Look at Oracle’s code: All the pthread_key updates and shuffling is painful and it would only get worse when there are multiple participating storage engines.