This is the first in a series of three articles about ideas for implementing full support for group commit in MariaDB (for the other parts see the second and third articles). Group commit is an important optimisation for databases that helps mitigate the latency of physically writing data to permanent storage. Group commit can have a dramatic effect on performance, as the following graph shows: 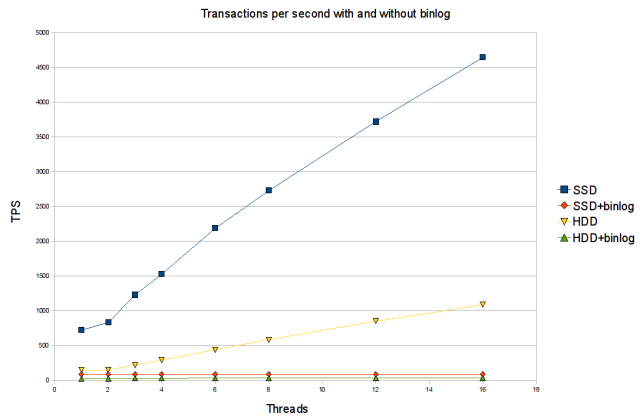
The rising blue and yellow lines show transactions per second when group commit is working, showing greatly improved throughput as the parallelism (number of concurrently running transactions) increases. The flat red and green lines show transactions per second with no group commit, with no scaling at all as parallelism increases. As can be seen, the effect of group commit on performance can be dramatic, improving throughput by an order of magnitude or more. More details of this benchmark below, but first some background information.
Durability and group commit
In a fully transactional system, it is traditionally expected that when a transaction is committed successfully, it becomes durable. The term durable is the “D” in ACID, and means that even if the system crashes the very moment after commit succeeded (power failure, kernel panic, server software crash, or whatever), the transaction will remain committed after the system is restarted, and crash recovery has been performed.
The usual way to ensure durability is by writing, to a transactional log file, sufficient information to fully recover the transaction in case of a crash, and then use the fsync() system call to force the data to be physically written to the disk drive before returning successfully from the commit operation. This way, in case crash recovery becomes necessary, we know that the needed information will be available. There are other methods than fsync(), including calling the fdatasync() system call or using the O_DIRECT flag when opening the log file, but for simplicity we will use fsync() to refer to any method for forcing data to physical disk.
fsync() is an expensive operation. A good traditional hard disk drive (HDD) will do around 150 fsyncs per second (10k rotation per minute drives). A good solid state disk like the Intel X25-M will do around 1200 fsyncs per second. It is possible to use RAID controllers with a battery backed up cache (which will keep data in cache memory during a power failure and physically write it to disk when the power returns); this will reduce the overhead of fsync(), but not eliminate it completely.
(There are other ways than fsync() to ensure durability. For example in a cluster with synchronous replication (like NDB or Galera), durability can be achieved by making sure the transaction is replicated fully to multiple nodes, on the assumption that a system failure will not take out all nodes at once. Whatever method used, ensuring durability is usually signficantly more expensive that merely committing a transaction to local memory.)
So the naive approach, which does fsync() after every commit, will limit throughput to around 150 transactions per second (on a standard HDD). But with group commit we can do much better. If we have several transactions running concurrently, all waiting to fsync their data in the commit step, we can use a single fsync() call to flush them all to physical storage in one go. The cost of fsync() is often not much higher for multiple transactions than for a single one, so as the above graph shows, this simple optimisation greatly reduces the overhead of fsync() for parallel workloads.
Group commit in MySQL and MariaDB
MySQL (and MariaDB) has full support for ACID when using the popular InnoDB (XtraDB in MariaDB) storage engine (and there are other storage engines with ACID support as well). For InnoDB/XtraDB, durability is enabled by setting innodb_flush_log_at_trx_commit=1.
Durability is needed when there is a requirement that committed transactions must survive a crash. But this is not the only reason for enabling durability. Another reason is when the binary log is enabled, for using a server as a replication master.
When the binary log is used for replication, it is important that the content of the binary log on the master exactly match the changes done in the storage engine(s). Otherwise the slaves will replicate to different data than what is on the master, causing replication to diverge and possibly even break if the differences are such that a query on the master is unable to run on the slave without error. If we do not have durability, some number of transactions may be lost after a crash, and if the transactions lost in the storage engines are not the same as the transactions lost in the binary log, we will end up with an inconsistency. So with the binary log enabled, durability is needed in MySQL/MariaDB to be able to recover into a consistent state after a crash.
With the binary log enabled, MySQL/MariaDB uses XA/2-phase commit between the binary log and the storage engine to ensure the needed durability of all transactions. In XA, committing a transaction is a three-step process:
- First, a prepare step, in which the transaction is made durable in the engine(s). After this step, the transaction can still be rolled back; also, in case of a crash after the prepare phase, the transaction can be recovered.
- If the prepare step succeeds, the transaction is made durable in the binary log.
- Finally, the commit step is run in the engine(s) to make the transaction actually committed (after this step the transaction can no longer be rolled back).
The idea is that when the system comes back up after a crash, crash recovery will go through the binary log. Any prepared (but not committed) transactions that are found in the binary log will be committed in the storage engine(s). Other prepared transactions will be rolled back. The result is guaranteed consistency between the engines and the binary log.
Now, each of the three above steps requires an fsync() to work, making a commit three times as costly in this respect compared to a commit with the binary log disabled. This makes it all the more important to use the group commit optimisation to mitigate the overhead from fsync().
But unfortunately, group commit does not work in MySQL/MariaDB when the binary log is enabled! This is the infamous Bug#13669, reported by Peter Zaitsev back in 2005.
So this is what we see in the graph and benchmark shown at the start. This is a benchmark running a lot of very simple transactions (a single REPLACE statement on a smallish XtraDB table) against a server with and without the binary log enabled. This kind of benchmark is bottlenecked on the fsync throughput of the I/O system when durability is enabled.
The benchmark is done against two different servers. One has a pair of Western Digital 10k rpm HDDs (with binary log and XtraDB log on different drives). The other has a single Intel X25-M SSD. The servers are both running MariaDB 5.1.44, and are configured with durable commits in XtraDB, and with drive cache turned off (drives like to lie about fsync to look better in casual benchmarks).
The graph shows throughput in transactions per second for different number of threads running in parallel. For each server, there is a line for results with the binary log disabled, and one with the binary log enabled.
We see that with one thread, there is some overhead in enabling the binary log, as is to be expected given that three calls to fsync() are required instead of just one.
But much worse, we also see that group commit does not work at all when the binary log is enabled. While the lines with binary log disabled show excellent scaling as the parallelism increases, the lines for binary log enabled are completely flat. With group commit non-functional, the overhead of enabling the binary log is enourmous at higher parallelism (at 64 threads on HDD it is actually two orders of magnitude worse with binary log enabled).
So this concludes the first part of the series. We have seen that if we can get group commit to work when the binary log is enabled, we can expect a huge gain in performance on workloads that are bottlenecked on the fsync throughput of the available I/O system.
The second part will go into detail with why the code for group commit does not work when the binary log is enabled. The third (and final) part will discuss some ideas about how to fix the code with respect to group commit and the binary log.
Thank you,
Now I understand XA better
Is the 150 fsyncs per second figure for random IO only? Is it higher for sequential IO or is it going to be the same?
I thought one effect of logs is to turn random IO into sequential IO. So if you put the binlog on its own dedicated disk, would that increase the binlog performance now that the only IO on that disk is sequential?
One general practice for database is to put logs on their own dedicated disks. Wondered if that would solve/help the problem here.
The 150 fsyncs per second is for sequential IO, as it is the log that is flushed to disk.
150 fsyncs is the upper limit for sequential IO as well as random IO. It comes from the fact that the disk rotates at 10000 rotations per minute, which is just over 150 times per second. To write a sector to disk it is necessary to wait for that sector to go past the write head.
So turning random IO into sequential, and putting logs on dedicated disks, can help get at close as possible to the approximately 150 fsync/sec limit, but cannot help to go past it.
Kristian,
Thanks for the explanation.
So the 150 fsyncs per sec limit holds even for sequential IO. Each sector is 512 bytes. If each fsycn writes to a sector, that means 150X512 = 75KB/s. Yet disks have a sequential write rate of about 100MB/s. What accounts for the huge difference between the two? How do you get the full 100MB/s sequential write rate if only 150 fsyncs can be done per second?
>”To write a sector to disk it is necessary to wait for that sector to go past the write head.”
Can’t consecutive fsyncs write on consecutive sectors without waiting for the disk to spin a full circle? So fsync #1 writes on sector #1. Immediately after that sector #2 rotates to the position underneath the write head. At that point fsync #2 writes on sector #2. In this scenario there’s no need to wait for sector #2 to go through another full cycle of spinning before writing onto it. Can it work this way?
In your graph that shows big performance drops when binlog was used, presumably no BBU was used for that benchmark, right?
Would using BBU eliminate the performance penalty of binlog or would significant penalty still remain even with BBU. Do you have any data on that?
Thanks
Andy
Re: fsync
The problem with fsync() is latency, not throughput. The latency to fsync() 100K sequential bytes (say) is not much higher than the time to fsync() a single byte. Since exactly as you say, all of the sectors can be written together on a single spin of the disk.
A normal disk write is asynchroneous. The application just sends the data to the disk controller, and the controller can then at its leasure write the data out to disk in the most efficient way, at 100MB/s or so as you say.
But fsync() is synchroneous, the application has to wait for the latency of the write, which turns out to be around 1/150 of a second in this case.
I do not know if you can artificially get much higher fsync() rate by guessing where the disk is at the exact moment where you call fsync(), and thus getting several syncs in per disk rotation. But in practice you are not able to guess this, or determine where you want to write based on micro-second resolution of the current time 🙂
You are correct that no BBU was used in the test. I do not have experience with BBU, but I asked some people from Percona about it, and they confirmed that BBU enourmeously improves the fsync() rate (I think a number like 10,000 fsync() per second was suggested). So I would expect the penalty to be much smaller with BBU.
Re: fsync
thank you for the great explanation, Kristian
But according to the MySQL bug tracker Bug#13669 has been fixed in InnoDB Plugin 1.0.4:
http://bugs.mysql.com/bug.php?id=13669
You’re saying it still doesn’t work? So what has been “fixed’ in Plugin 1.0.4 then?
Group commit only works when binlog is disabled
For bug#13669, they fixed only group commit in the case where the binary log is disabled.
Before innodb plugin 1.0.4 group commit doesn’t work even when the binary log is disabled.
Starting from innodb plugin 1.0.4 (and xtradb includes this), group commit does work when the binary log is disabled, as the benchmark shows. But group commit still does not work when the binary log is enabled.
Arguably, it is not correct to have marked bug#13669 as fixed, as the fix is only partial.
Presumably the results in your graph were obtained by setting
sync_binlog=1
innodb_support_xa=1
What if you set:
sync_binlog=0
innodb_support_xa=0
In this case binlog data isn’t sync to disk on every commit. In a sense the OS is “grouping” a bunch of commits into one fsync(). With this setting would the performance be the same as having group commit fixed? Or is there still going to be some performance penalty here?
I understand that setting sync_binlog to 0 means no durability. But for data that is not critical would this be an acceptable workaround until the binlog group commit is fixed?
fsync() / XA is needed to be able to recover after a crash
It is not just durability that is lost with sync_binlog=0 and innodb_support_xa=0. You also loose the ability to recover to a consistent state after a crash.
In this case, if the server crashes, InnoDB may loose the last M transactions, and the binary log may loose the last N transactions. The point is that you can have M different from N. So when the server comes back up after the crash, there can be transactions in InnoDB not present in the binary log (or vice versa).
So any existing replication slaves that try to reconnect to a crashed master after it recovers may end up being inconsistent with the master. They will replicate what is in the binary log, which may contain more transactions than what InnoDB has on the master, or less. This in turn will probably sooner or later cause replication to break.
On the other hand, if one is able to discard the binary log on a crashed server and start over (setting up any slaves from scratch or maybe restoring the crashed server from a backup), then yes, the performance problems with fsync can be eliminated by the settings suggested. Setting innodb_flush_log_at_trx_commit=2 will also help in this case.
What’s your benchmark software?
Is it all write benchmark ?
We’ve tested in sysbench oltp with new PerconaDB, however no such huge improvement has been observed.
I used Gypsy. Yes, it is a write benchmark.
Group commit improves performance when sync_binlog=1 and innodb_flush_log_at_trx_commit=1. Without those settings, there are small speedups, if any.
Group commit is enabled by default in MariaDB 5.3 and 5.5. I do not know about Percona Server, maybe there it needs to be explicitly enabled.