(No three–part series is complete without a part 4, right?)
Here is an analogy that describes well what group commit does. We have a bus driving back and forth transporting people from A to B (corresponding to fsync() “transporting” commits to durable storage on disk). The group commit optimisation is to have the bus pick up everyone that is waiting at A before driving to B, not drive people one by one. Makes sense, huh? 🙂
It is pretty obvious that this optimisation of having more than one person in the bus can dramatically improve throughput, and it is the same for the group commit optimisation. Here is a graph from a benchmark comparing stock MariaDB 5.1 vs. MariaDB patched with a proof-of-concept patch that enables group commit: 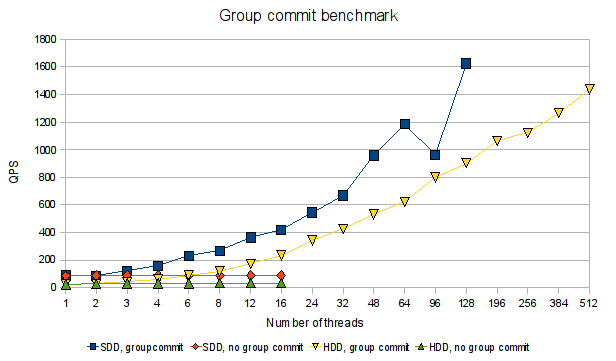
When group commit is implemented, we see clearly how performance (measured in queries per second) scales dramatically as the number of threads increases. Whereas with stock MariaDB with no group commit, there is no scaling at all. We also see that SSD is better than HDD (no surprise there), but that with sufficient parallelism from the application, group commit can to a large extent compensate for the slower disks.
This is the same benchmark as in the first part of the series. Binlog is enabled. Durability is enabled with sync_binlog=1 and flush_log_at_trx_commit=1 (and disk cache disabled to prevent the disks lying about when data is durable). The load is single-row transactions against a 1000000-row XtraDB table. The benchmark is thus specifically designed to make the fsync() calls at the end of commit the bottleneck.
I should remark that I did not really tune the servers used in the benchmark for high parallelism (except for raising max_connections 🙂), and I ran the client on the same machine as the server. So it is likely that there are other effects than group commit influencing the performance at high parallelism (especially on the SSD results, which I ran on my laptop). But I just wanted to see if my group commit work scales with higher parallelism, and the graphs clearly shows that it does!
Architecture
For this work, I have focused a lot on the API for storage engine and binlog plugins (we do not have binlog plugins now, but this is something that we will be working on in MariaDB later this year). I want a clean interface that allows plugins to implement group commit in a simple and efficient manner.
A crucial point is the desire to get commits ordered the same way in the different engines (ie. typically in InnoDB and in the binlog), as I discussed in previous articles. As group commit is about parallelims, and ordering is about serialisation, these two tend to get into conflict. My idea is to introduce new calls in the interface to storage engines and the XA transaction coordinator (which is how binlog interacts with commit internally in the server). These new calls allow plugins that care about commit order to cooperate on getting correct ordering without getting in each others way and killing parallelims. Plugins that do not need any ordering can ignore the new calls, which are optional (for example the transaction coordinator that runs when the binlog is disabled does not need any ordering).
The full architecture is written up in detail in the MariaDB Worklog#116. But the basic idea is to introduce a new handlerton method:
void commit_ordered(handlerton *hton, THD *thd, bool all);
This is called just prior to the normal commit() method, and is guaranteed to run in the same commit order across all engines (and binlog) participating in the transaction.
This allows for a lot of flexibility in plugin implementations. A typical implementation would in the commit_ordered() method write the transaction data into its in-memory log buffer, and delay the time-consuming write() and fsync() to the parallel commit() method. InnoDB/XtraDB is already structured in this way, so fits very well into this scheme.
But if an engine wants to use another approach, for example a ticket-based approach as Mark and Mats suggested, that is easy to do too. Just allocate the ticket in commit_ordered(), and use it in commit(). I believe most approaches should fit in well with the proposed model.
I also added a corresponding prepare_ordered() call, which runs in commit order during the prepare phase. The intension is to provide a place to release InnoDB row locks early for even better performance, though I still need to get the Facebook people to explain exactly what they want to do in this respect 😉
I also spent a lot of thought on getting efficient inter-thread synchronisation in the archtecture. As Mats mentioned, if one is not careful, it is easy to end up with O(N2) cost of thread wake-up, with N the number of transactions participating in group commit. As the goal is to get N as high as possible to maximise sharing of the expensive fsync() call, such O(N2) cost is to be avoided.
In the architecture described in MariaDB Worklog#116, there should in the normal case only be a single highly contested lock, the one on the binlog group commit (which is inherent to the idea of group commit, one thread does the fsync() while the rest of participating threads wait). I use a lock-free queue to make threads in prepare_ordered() not block threads in commit_ordered() and vice versa. The prepare_ordered() calls runs under a global lock, but as they are intended to execute very quickly there should ideally be little contention here. The commit_ordered() calls run in a loop in a single thread, also avoiding serious lock contention as long as commit_ordered() runs quickly as intended.
In particular, running the commit_ordered() loop in a single thread for each group commit avoids high cost of thread wake-up. If we were to try to run the sequential part of commit in different threads in a specific commit order, we would need to switch execution context from one thread to the next, bouncing the thread of control all over the cores in an SMP system. Which takes lots of context switches, and could potentially be costly. In the proposed architecture, a single thread runs all commit_ordered() method calls and wakes up the other waiting threads individually, each free to proceed immediately without any more waiting for one another.
Of course, an engine/binlog plugin that so desires is free to implement such thread-hopping itself, by allocating a ticket in one of the _ordered() methods, and doing its own synchronisation in its commit() method. After all, it may be beneficial or necessary in some cases. The point is that different plugins can use different methods, each using the one that works best for that particular engine without getting in the way of each other.
Further improvements
If we implement this approach, there are a couple of other interesting enhancements that can be implemented relatively easy due to the commit ordering facilities:
- Currently, we sync to disk three times per commit to ensure consistency between InnoDB and binlog after a crash. But if we know the commit order is the same in engine and in binlog, and if we store in the engine the corresponding binlog position (which InnoDB already does), then we need only sync once (for the binlog) and can still recover reliably after a crash. Since we have a consistent commit order, we can during crash recovery replay the binlog from the position after the last not lost commit inside InnoDB (just like we would apply the binlog on a slave).
- Currently, the
START TRANSACTION WITH CONSISTENT SNAPSHOT, which is supposed to run a transaction with a consistent view in multiple transactional engines, is not really all that consistent. It is quite possible to see a transaction committed in one engine but not in another, and vice versa. However, with an architecture like the one proposed here, it should be easy to just take the snapshot under the same lock thatcommit_ordered()runs under, and the snapshot will be really consistent (on engines that support commit order). As a bonus, it would also be possible to provice a binlog position corresponding to the consistent snapshot. - XtraDB (and similar backup solutions) should be able to create a backup which includes a binlog position (suitable for provisioning a new slave) without having to run
FLUSH TABLES WITH READ LOCK, which can be quite costly as it blocks all transaction processing while it runs. - As already mentioned, the Facebook group has some ideas for releasing InnoDB row locks early in order to reduce the load on hot-spot rows; this requires consistent commit order.
Implementation
If anyone is interested in looking at the actual code of the proof-of-concept implementation, it is available as a quilt patch series and as a Launchpad bzr tree (licence is GPLv2).
Do be aware that this is work in progress.
As with the hitchhiker’s guide to the galaxy
The subtitle for the fifth book, “Mostly Harmless” was:
“The increasingly inaccurately named hitchhiker’s trilogy”
Updates
I updated the patch series and launchpad tree with a couple of fixes for some race conditions in the code.
Pretty! This was an extremely wonderful post. Many thanks for supplying this info.
Ditto
Ditto. Many thanks for the clare explanation!