Parallel replication is in MariaDB 10.0. I did some benchmarks on the code in 10.0.9. The results are quite good! Here is a graph that shows a 10-times improvement when enabling parallel replication:
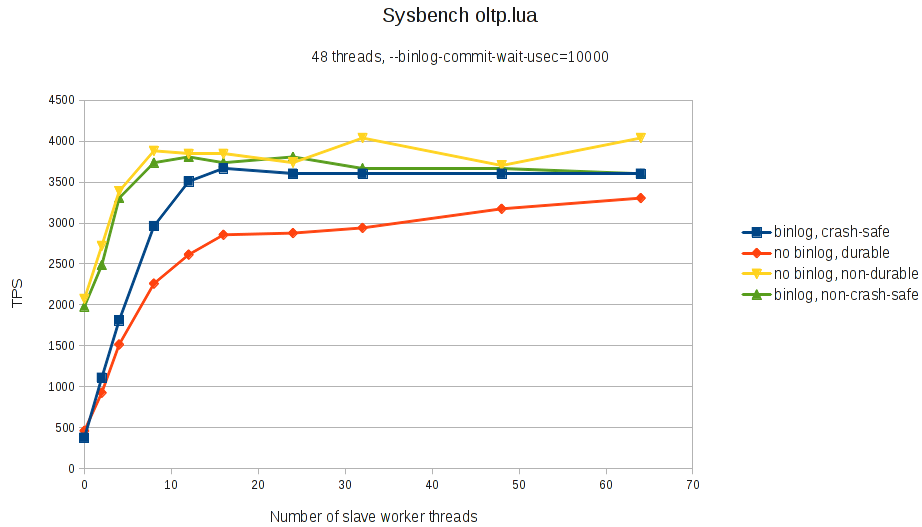
The graph shows the transaction per second as a function of number of slave worker threads, when the slave is executing events from the master at full speed. The master binlog was generated with sysbench oltp.lua. When the binlog is enabled on the slave and made crash-safe (--sync-binlog=1 --innodb-flush-log-at-trx-commit=1), the slave is about ten times faster at 12 worker threads and above compared to the old single-threaded replication.
These results are for in-order parallel replication. With in-order, transactions are committed on the slave in strictly the same order as on the master, so that applications do not see any differences from using parallel replication. So no changes to the application are needed to use parallel replication; this is just standard sysbench 0.5 with a single table. This makes parallel replication particularly interesting, as it can be used with any existing applications, without the need to eg. split the data into independent schemas as is necessary with out-of-order techniques like the multi-threaded slave feature in MySQL 5.6. It does however make it much harder for the slave to find parallelism to exploit in the events received from the master, which is why it is interesting to see how much improvement can be obtained from normal workloads.
(MariaDB 10.0 does also support out-of-order parallel replication, but that will be the subject of a different article).
The hardware used for the sysbench oltp.lua is the same machine I used to benchmark group commit previously; I am told this is a machine that is typical for a “standard” datacenter server, with decent I/O on a RAID controller with battery-backed-up cache. Sysbench was run with 10 million rows in one table. The mysqld was configured with 16GB buffer pool and 2 times 1.9 gigabyte redo logs. The different graphs are as follows:
- binlog, crash-safe:
--log-slave-updates --sync-binlog=1 --innodb-flush-log-at-trx-commit=1 - no binlog, durable:
--skip-log-slave-updates --innodb-flush-log-at-trx-commit=1 - no binlog, non-durable:
--skip-log-bin --innodb-flush-log-at-trx-commit=2 - binlog, non-crash-safe:
--log-slave-updates --sync-binlog=0 --innodb-flush-log-at-trx-commit=0
For this test, the master was configured with --binlog-commit-wait-count=12 --binlog-commit-wait-usec=10000. This allows the master to delay a transaction up to 10 milliseconds in order to find up to 12 transactions that can commit in parallel; this helps a lot in improving parallel replication performance, since transactions that commit in parallel on the master can be executed in parallel on the slave.
Adding such delay will be acceptable for many applications to speed up the slaves; in fact in my test it did not affect master throughput at all. One attractive option might be to set up monitoring of the slaves, and if they start falling behind, then the commit delay on the master can be temporarily increased, throttling the master a bit while allowing slaves better possibility to catch up.
The other source of parallelism on the slave is that irrespectively of how the transactions were executed on the master, the commit steps of different transactions can always be applied in parallel on the slave. This is particularly effective at improving performance when the commit step is expensive, as happens when a durable, crash-safe configuration is used. This is seen in the benchmark, where the speedup is particularly large when the slave is configured to be crash-safe and durable, to the point where parallel replication almost eliminates any performance penalty for enabling crash-safe binlog on the slaves. But significant speedup is seen in all the configurations.
(In fact, if you look closely, you will see that turning off the binlog ends up decreasing the performance of the slave. This is bug MDEV-5802, and performance should improve when binlog is disabled when this bug is fixed).
I think these are very promising results. I hope this will inspire users to give the new feature a test on real workloads, and share their experiences.
Exploring the limits of parallel replication
I also wanted to see how the code works for workloads that are not favorable to parallel replication. For this I use sysbench update_index.lua. This benchmark creates transactions with a single primary-key update. With just 10 million rows in the table, the test is in-memory, and the actual work spent for the single-row update is rather small compared to the overhead of reading and parsing binlog events and scheduling the work between the various replication threads. So it is interesting to see if parallel replication can still give some smaller benefit here, or at least not make things much worse.
Here are the results for an update_index.lua with 48 threads for the load on the master. No commit delay was used to help the parallel replication (–binlog-commit-wait-count=0):
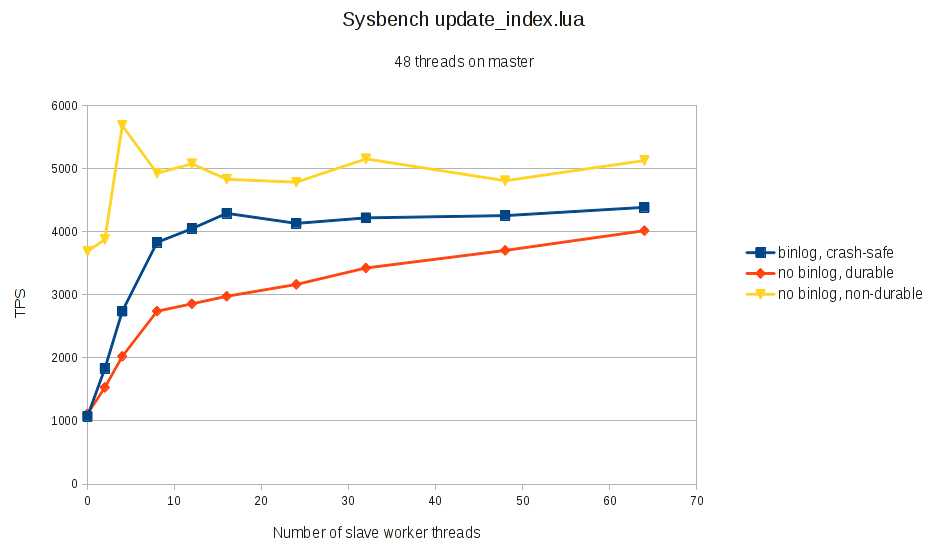
As can be seen, even in this workload there is significant improvement from parallel replication. Again, the improvement is particularly high when commit is expensive, due to the possibility to do the commits in parallel and amortise the cost using group commit. But even with binlog disabled and non-durable InnoDB commit, we see some improvement, though only a modest one.
Finally, to test the absolutely worst-case scenario for parallel replication, I created another workload on the master, this time with update_index.lua running with just a single thread. This way, there is absolutely no opportunity for parallel replication to execute the actual transactions in parallel, though there is still some opportunity to speed up the commit step using group commit.
Here are the results for the single-threaded update_index.lua master load:
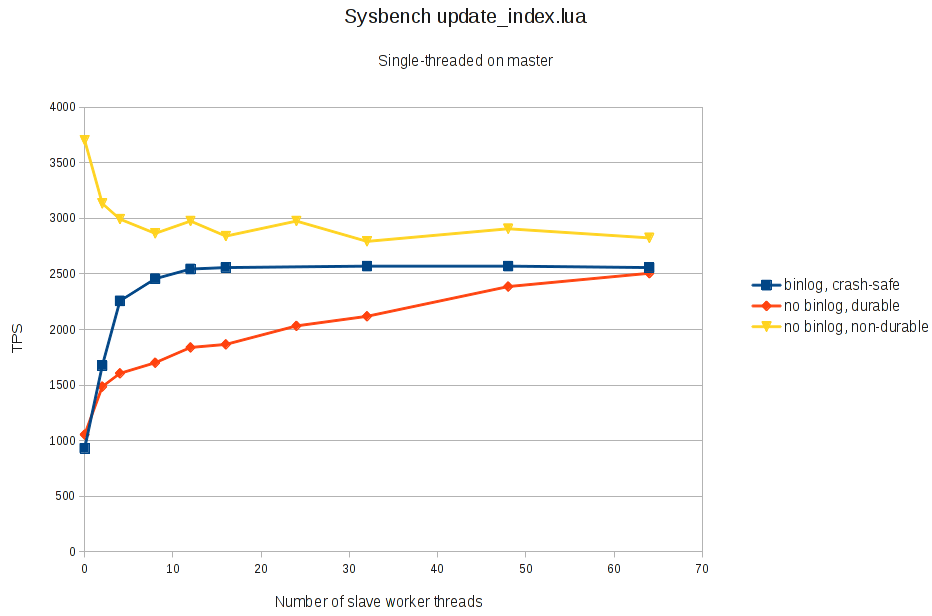
As can be seen, even in this extreme case, we do see some speedup when commits are expensive (durable/crash-safe configuration). But when durability and crash-safety is turned off, and commits are cheap, then the overhead of the extra thread scheduling shows, and the results of parallel replication are worse, if not disastrously so. Note by the way that with this test, the time taken by the slave to replicate the load was smaller than the time for the master to generate it with single-threaded sysbench.
Conclusions
So overall, I am pleased with the results of the parallel replication code in MariaDB 10.0. Single-threaded applier has been a major limitation in replication for a long, long time, and I feel now fairly confident that this can play an important part in solving that. I hope this will inspire users to start testing their own loads and hopefully getting good results and/or reporting any issues found on the way.
To test, use MariaDB 10.0.9 or later on both master and slave. Configure the slave with --slave-parallel-threads=20 or something like that. And optionally, if your application can tolerate some extra commit latency, set some reasonable values for --binlog-commit-wait-count and --binlog-commit-wait-usec.
Kristian love your work and thanks for sharing your findings. Always a pleasure to learn more from your work 🙂
Kristian,
You’ve done a fantastic job with replication in MariaDB 10! Thanks for all the hard work, I can see the results are great!
-ivan
Excellent post. I will be dealing with some of these issues ass well..
I’m running 2 Servers (MariaDB 10.0.11, Ubuntu 12.04, running in KVM VM’s with virtio and cache=none) as Master-Slave Replication using Statement based binlog with your binlog, crash-safe settings and end up in constantly growing lag of the slave to the master.
The Slave (8 Cores) is actually configured slave_parallel_threads = 8 since it has 8 Cores.
Both servers (8 Cores) are far away from having high load/high I/O. Master has about 250 Queries per second.
I sysbenched the servers and get 350 I/O’s per second on the slave about in iostat output on HDD. The Master has mixed SSD and HDD setup to have the *.ibd and old myisam files on SSD and binlog, double-buffer on HDD.
sar -b on the Master shows an average of 127tps, sar -b on the slave only 56tps.
SHOW ALL SLAVES STATUS shows constantly: Slave_SQL_State: Waiting for room in worker thread event queue.
I’m running a hand full of master slave pairs with MySQL 5.5 (single threaded replication) and don’t have comparable problems even if they are running at about 1000 Queries/second.
Can anybody give me a hint ?
It is not possible to say what your problem is from this. You need to determine what the bottleneck is for the performance of your slave.
Thats my problem: I did test the slave in all regards of performance and the slave replication seems to be sleeping even if the system is not loaded at all and I/O is far away from a congestion. I constantly measured iostat i.e. and see only ~60tps even if the system, is able to handle about 350tps and slave is lagging behind. CPU Cores are sleeping, too and memory is much bigger than needed.
I want the slave to use _all_ the resources to catch up the lag, but it doesn’t even try to.
Please enlighten me what the state “Slave_SQL_State: Waiting for room in worker thread event queue” tells me.
I’m not expecting to never have a lag between master and server in highload times but both servers are comparable and average use is low.
> Please enlighten me what the state “Slave_SQL_State: Waiting for room in
> worker thread event queue” tells me.
It means that the SQL thread has read as far ahead in the log as the value of –slave-parallel-max-queued allows. So the worker threads are lagging behind.
If you want more parallelism on the slave, then one way is to increase group commit on the master. Check SHOW STATUS if binlog_commits is much larger (several times) than binlog_group_commits. If not, you can increase group commit (and hence parallelism on the slave) by increasing –binlog-commit-wait-count and –binlog-commit-wait-usec on the master, but you need to watch that you don’t get too big a performance hit from it on the master.
Another way to get more parallelism on the slave is if you can use GTID and partition your changes into independent sets; then you can assign a different gtid_domain_id in each set, and the slave will be able to do them in parallel.
Check docs for parallel replication and GTID for more, or ask again…